
5 Things AI Investors Need to Know
The industry's most important AI inference benchmark just released results. Here's what the data says for NVDA, AMD, NBIS, and CRWV investors.

#1 NVIDIA Chips Won Every Single Benchmark. All 11 of Them.
MLPerf v6.0 covers 11 benchmark families: DeepSeek-R1, GPT-OSS-120B, LLaMA2-70B, LLaMA3.1-8B, LLaMA3.1-405B, Mixtral, DLRM-v3, Qwen3-VL, RGAT, WAN-2.2, and Whisper. These are the workloads running in production AI systems right now.
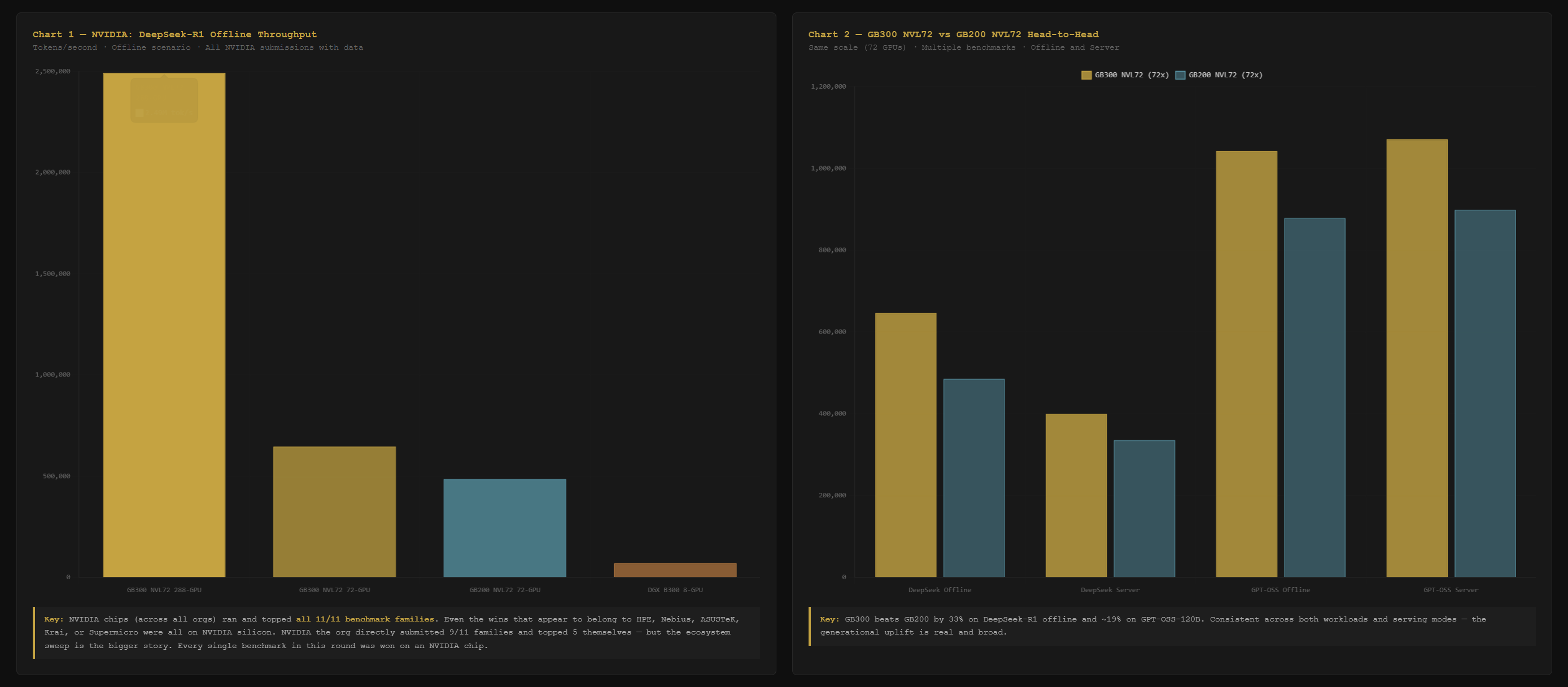
NVIDIA (NVDA) chips topped all 11. Not NVIDIA the company directly in every case. But every benchmark that ran was won on an NVIDIA chip. The wins that look like they belong to HPE, Nebius, ASUSTeK, Krai, and Supermicro? All NVIDIA silicon underneath.

The generational story inside NVIDIA's results is just as important. The GB300 NVL72 at 72 GPUs delivers 647,076 tokens per second on DeepSeek-R1. The GB200 NVL72 at identical scale delivers 486,141. That is a 33% lift, validated by an independent benchmark.
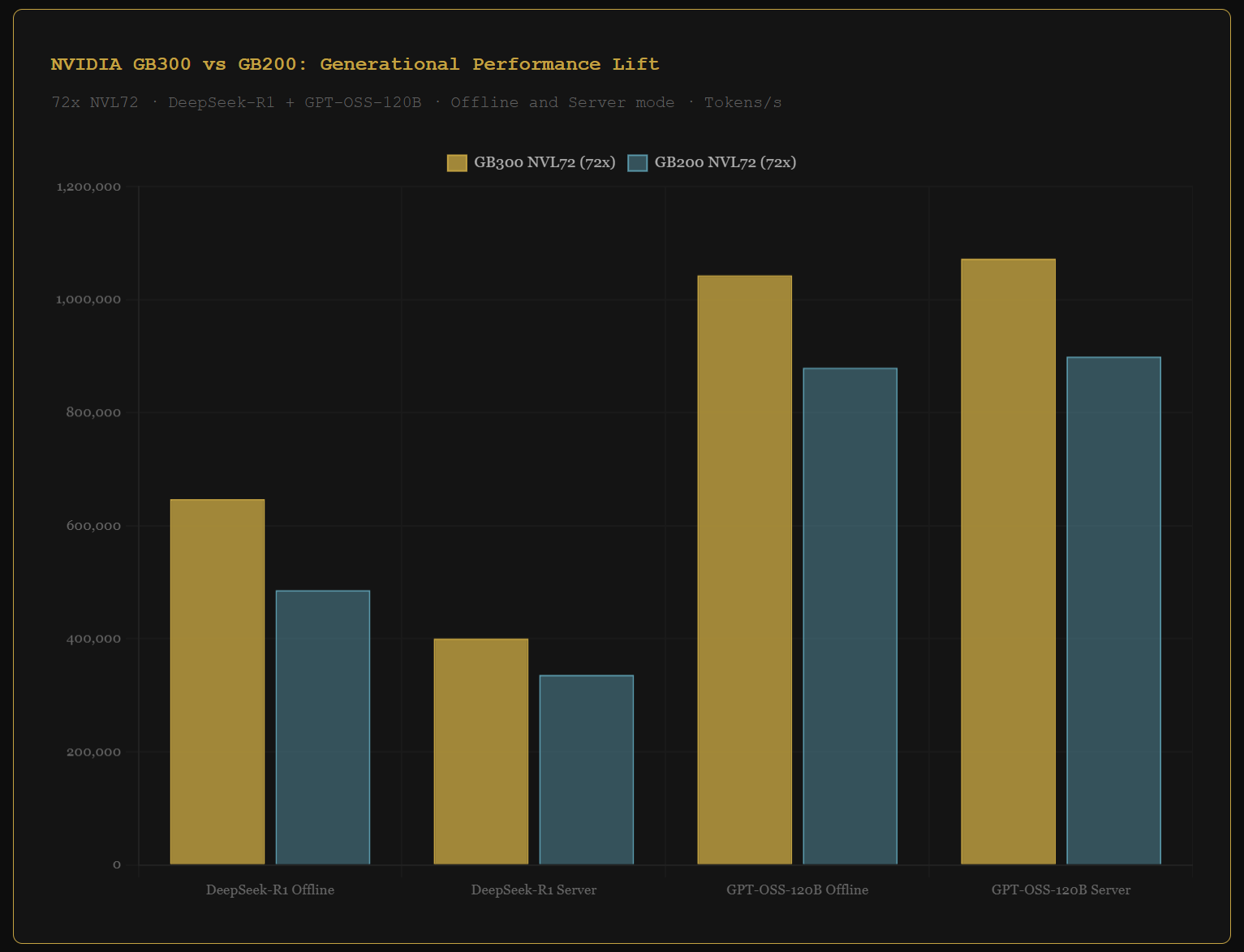
Investor read: NVIDIA’s chip dominance in this round is not a close race. It is every benchmark, every workload type, every scale. The upgrade cycle from GB200 to GB300 is confirmed by independent data at a 33% improvement. That is the recurring revenue argument for NVDA’s data center segment.
#2 AMD's MI355X Is a 189% Per-Chip Leap. But AMD Only Ran 2 of 11 Benchmarks.
AMD (AMD) submitted results on the MI355X across 3 configurations. They covered 2 of 11 benchmark families: GPT-OSS-120B and LLaMA2-70B. AMD silicon did not run DeepSeek-R1, any LLaMA3 variant, Mixtral, Qwen3, DLRM, RGAT, WAN-2.2, or Whisper.
On both families AMD did run, NVIDIA silicon won. At cluster scale, AMD needs 21 to 31 percent more chips than NVIDIA to reach comparable throughput. That chip count premium is the core bear case for AMD in AI inference.
The bull case is the generational leap. The MI355X posts 12,935 tokens per second per chip on LLaMA2-70B. The prior generation MI325X posts 4,235. That is a 189% improvement in one generation.
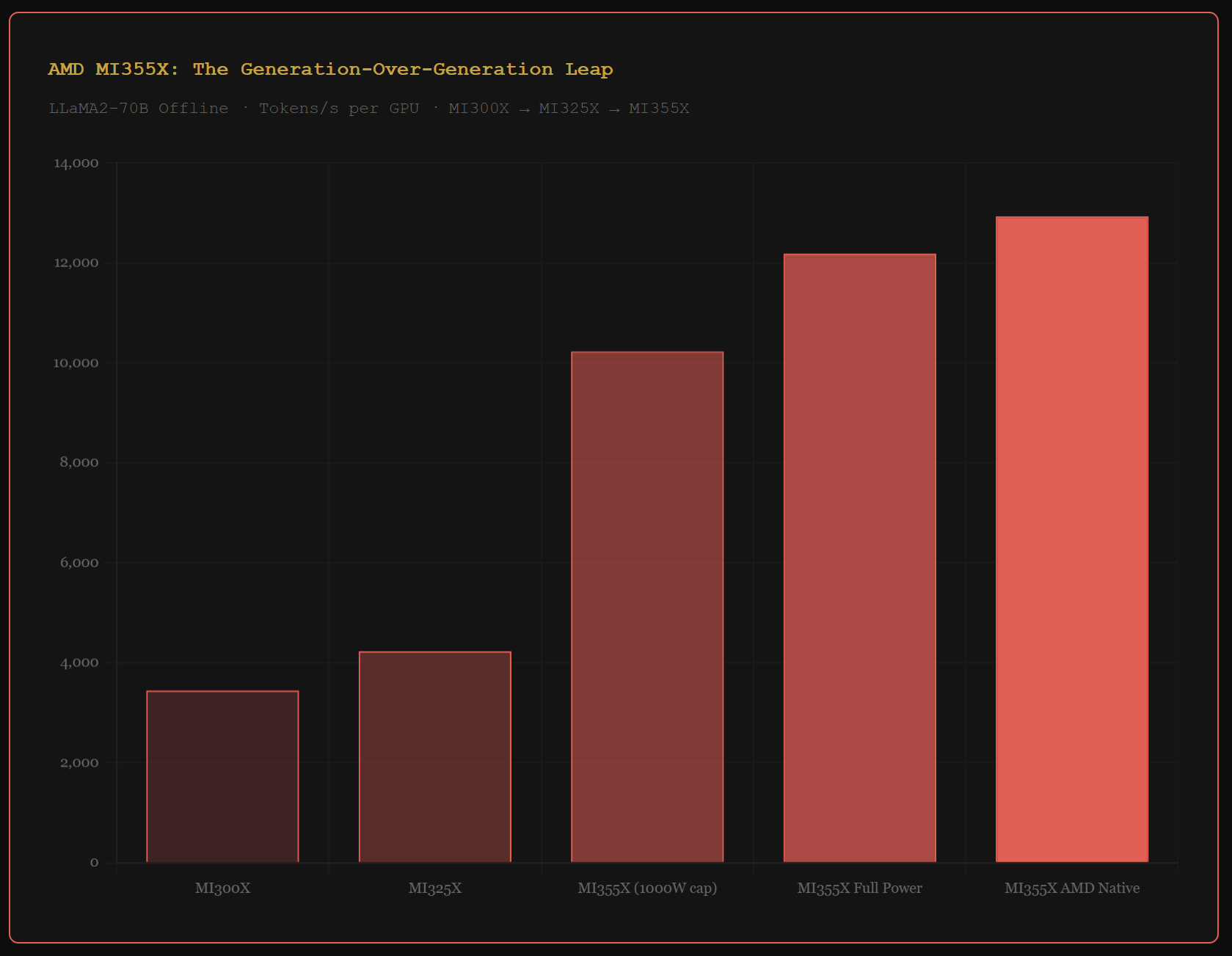
Investor read: The MI355X per-chip improvement is real and significant. But 2 of 11 benchmark families tells you the software stack is not yet enterprise-broad. That is the gap AMD needs to close before hyperscalers run mixed workloads on AMD silicon.
#3 Nebius Beat NVIDIA on NVIDIA's Own Chip. In Production Mode, by 44%.
Nebius (NBIS) ran the same GB300 NVL72 hardware as NVIDIA’s own submission. On GPT-OSS-120B, Nebius’s 72-GPU system posts 1,046,150 tokens per second offline. NVIDIA’s own system posts 1,042,980. Nebius wins.
The offline gap is 0.3%. The server mode gap is 44%.
Server mode measures how a system handles real concurrent requests under latency constraints. That is actual production traffic, not batch processing. On DeepSeek-R1 server mode with the same hardware, Nebius posts 575,580 tokens per second. NVIDIA posts 400,437.
Investor read: A cloud company that out-optimizes NVIDIA's own engineers on NVIDIA's own chip has a software moat. The server mode gap is not a rounding error. It means Nebius has specifically tuned their inference stack for live production traffic in a way that beats the reference implementation by 44%. For NBIS investors, this is the clearest public evidence that Nebius is building something more than a GPU rental business.
#4 CoreWeave's Server Mode Beat Its Own Offline Score. That Does Not Happen.
CoreWeave (CRWV) submitted a 64-GPU GB300 NVL72 configuration on GPT-OSS-120B. Offline mode: 910,468 tokens per second. Server mode: 956,523.
Server mode beat offline by 5%. This does not normally happen. Offline processes requests in large batches with no latency constraints. It should always be faster. When server mode exceeds offline, it means the inference stack has been specifically tuned to generate higher sustained throughput under live concurrent load.
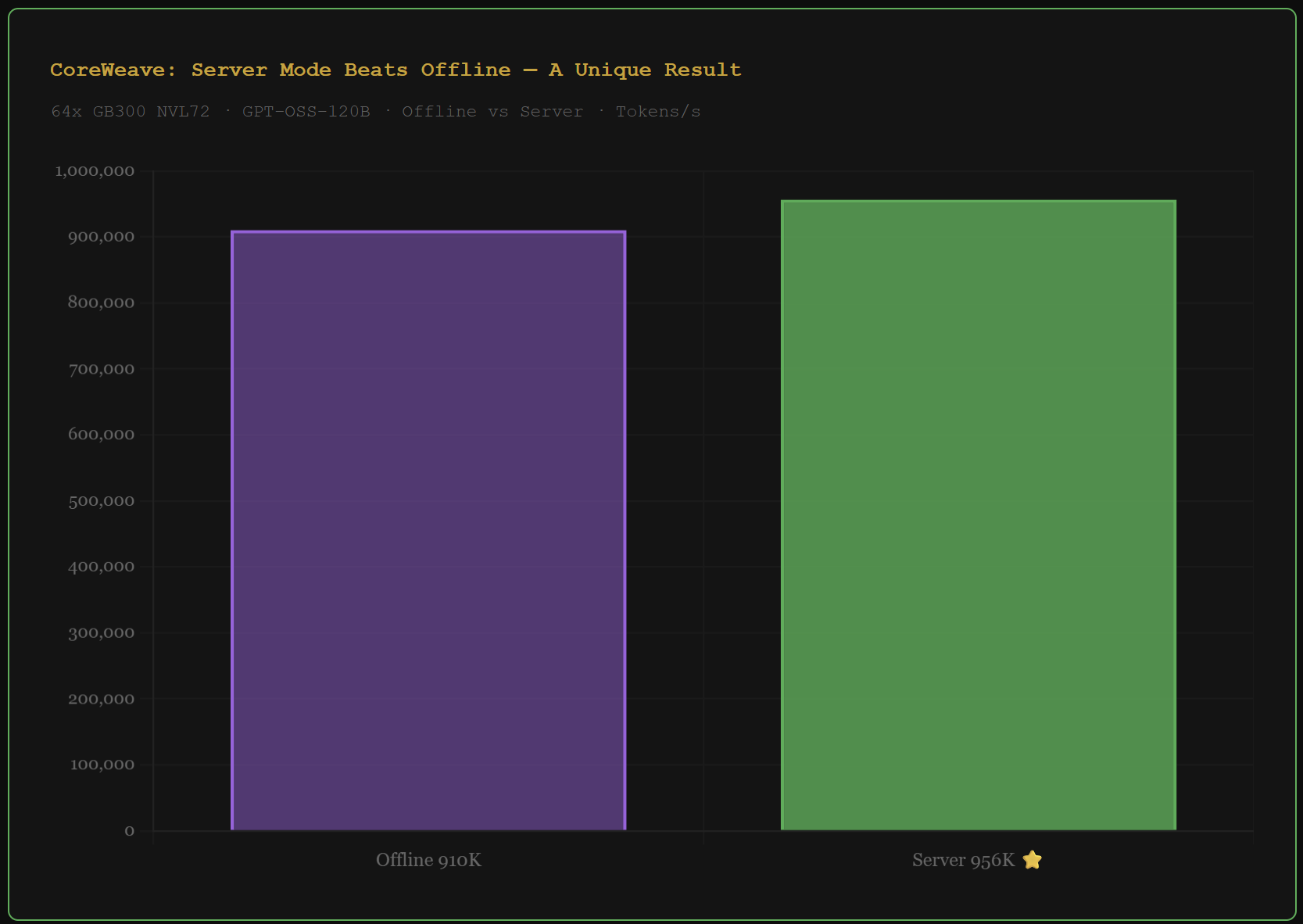
No other organization in this benchmark round shows this behavior. CoreWeave also posts the highest per-chip efficiency of any 8-GPU system in the round on DeepSeek-R1, beating NVIDIA's own DGX B300 submission.
Investor read: CoreWeave topped 0 benchmark families on the leaderboard. That framing misses the signal entirely. The server-beats-offline anomaly is unique in this dataset. It indicates a production serving stack engineered specifically for the workloads enterprise AI customers are actually running, not benchmark conditions.
#5 What the AMD Heterogeneous Cluster Tells You About Upgrade Cycles
Dell and MangoBoost submitted a 24-GPU cluster mixing 8x MI300X, 8x MI325X, and 8x MI355X chips in the same system. This is the only heterogeneous GPU cluster submission in the entire round.
Total throughput on LLaMA2-70B: 151,843 tokens per second. The per-chip average across the 24 mixed GPUs: 6,327 tokens per second. Pure MI355X nodes post 12,935 per chip. The MI300X chips pulled the cluster average down nearly in half.
Investor read: Hyperscalers will not mix GPU generations in production clusters. The efficiency penalty is too severe. This data confirms that AI infrastructure upgrade cycles are not optional. They are structural. Every generation of MI355X deployed today becomes a future replacement cycle for AMD. That is a constructive long-term data point for AMD investors even if today's numbers are mixed.
MEMBERS CoreWeave vs Nebius direct head-to-head across every comparable configuration
MEMBERS Full 8-GPU market ranking — every B300 and B200 system ranked by per-chip efficiency
MEMBERS Benchmark scorecard for each company — which models ran, which they led
MEMBERS AMD generation ladder: MI300X → MI325X → MI355X per-chip evolution chart
Disclaimer: This article is intended for educational and informational purposes only and should not be construed as investment advice. Always conduct your own research and consult with a qualified financial advisor before making any investment decisions.