
MLPerf Training v6.0: NVIDIA Ran The Table
The new benchmark round just dropped. Here is the read for NVIDIA, AMD, and the GPU clouds, in five charts.

MLPerf is the closest thing the AI hardware market has to a referee. Vendors submit real systems running real training jobs, the times are published, and everyone gets to see who actually shows up.
The v6.0 round landed with 227 submitted results across 24 organizations and 7 workloads. I pulled the full table apart and built it out to two dozen charts. Here are the five that matter most for the trade, and the one structural shift almost nobody is talking about.
Lower numbers are better throughout. Every figure is time-to-train in minutes, computed straight from the published results table.
1. NVIDIA showed up everywhere. AMD showed up on three of seven.
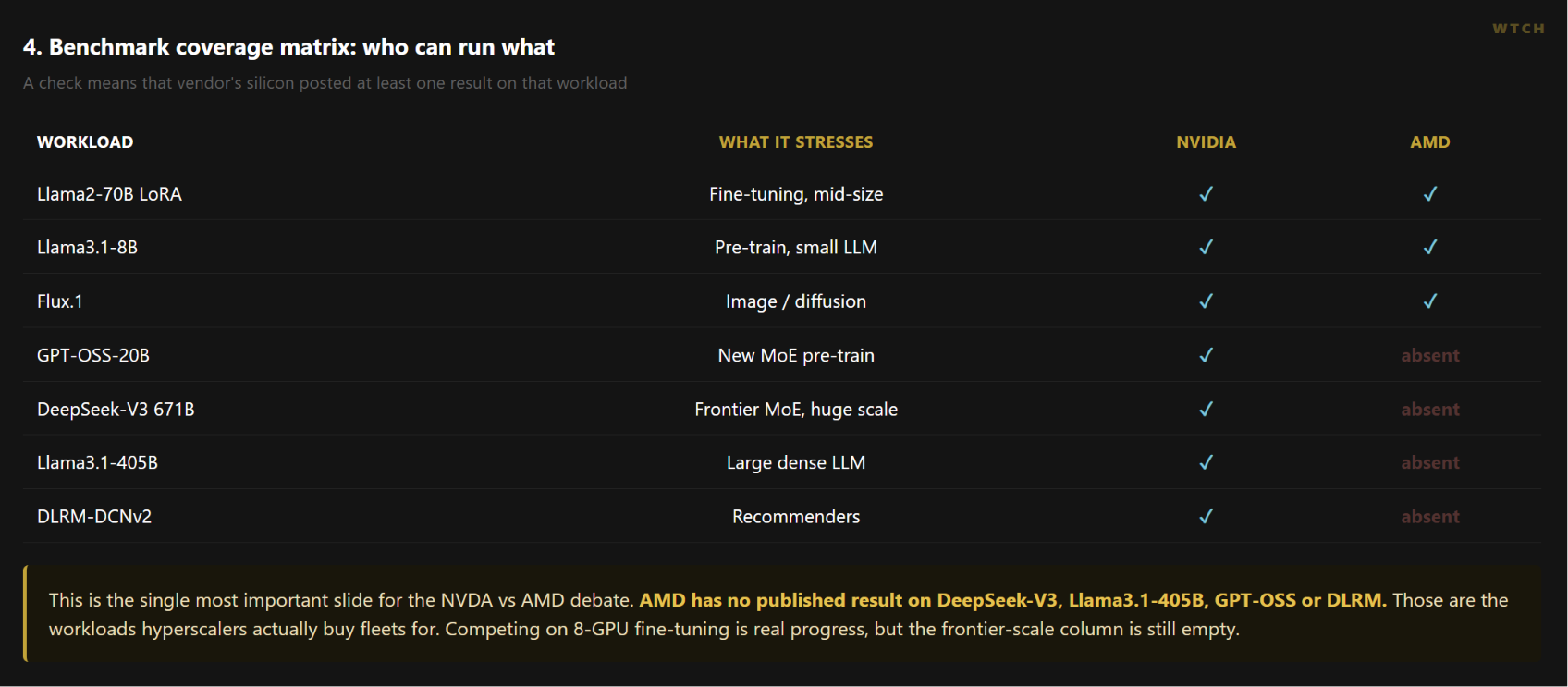
The first read is the simplest. NVIDIA (NVDA) silicon appears on 197 of 227 results, about 87 percent of everything submitted. It posted a result on all 7 workloads.
AMD (AMD) silicon appears on 30 results and only 3 workloads: Llama2-70B LoRA, Llama3.1-8B, and Flux.1.
The four workloads AMD sat out are the ones that define frontier training. There is no published AMD result on DeepSeek-V3 671B, Llama3.1-405B, GPT-OSS-20B, or the DLRM recommender. Those are the jobs hyperscalers buy fleets of GPUs to run.
What it means for investors. Remember that MLPerf is opt-in. Partners only publish configurations that look good, so this is the optimistic case for the field, and NVIDIA is still on nearly nine of every ten results. The coverage gap is the single most important fact in the NVDA-versus-AMD debate right now.
Get the full dashboard inside the community
I built the complete breakdown into an interactive dashboard: 20+ charts across seven angles, every one branded and ready to read, covering NVDA, AMD, CRWV, NBIS, the OEM channel, the scale leaderboard, and the precision war in full.
It is posted in the What The Chip Happened community, alongside various other dashboards covering Taiwan Supply Chain, Neocloud Players, and more.
Join the community and get the full 20+ chart MLPerf Training v6.0 dashboard →
Members get the dashboard, the live data tooling, and the tiered analysis on every name above. New members save 33 percent.
2. Blackwell Ultra is the number that justifies the refresh.
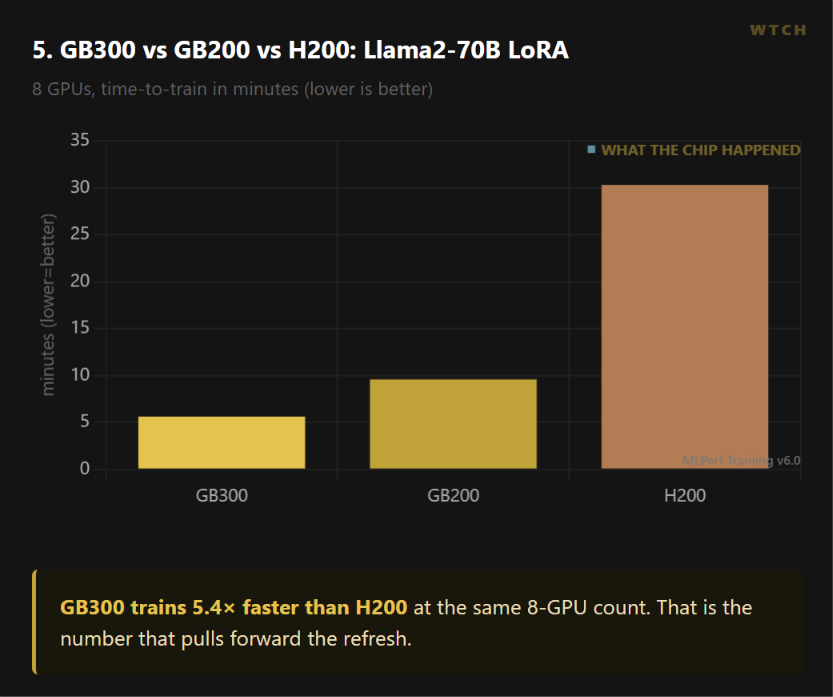
This is the round where GB300 (Blackwell Ultra) shows what it does to the prior generation.
On Llama2-70B LoRA at 8 GPUs, GB300 finishes in 5.61 minutes. The same job on H200 (Hopper) takes 30.31 minutes. That is a 5.4x generational speedup at the same GPU count. On Llama3.1-8B pre-training the uplift is 4.05x.
The jump is not just a single-chip story. GB300 scales a 671-billion-parameter DeepSeek-V3 run cleanly out to 8,192 GPUs. The interconnect is doing the heavy lifting there, not the spec sheet.
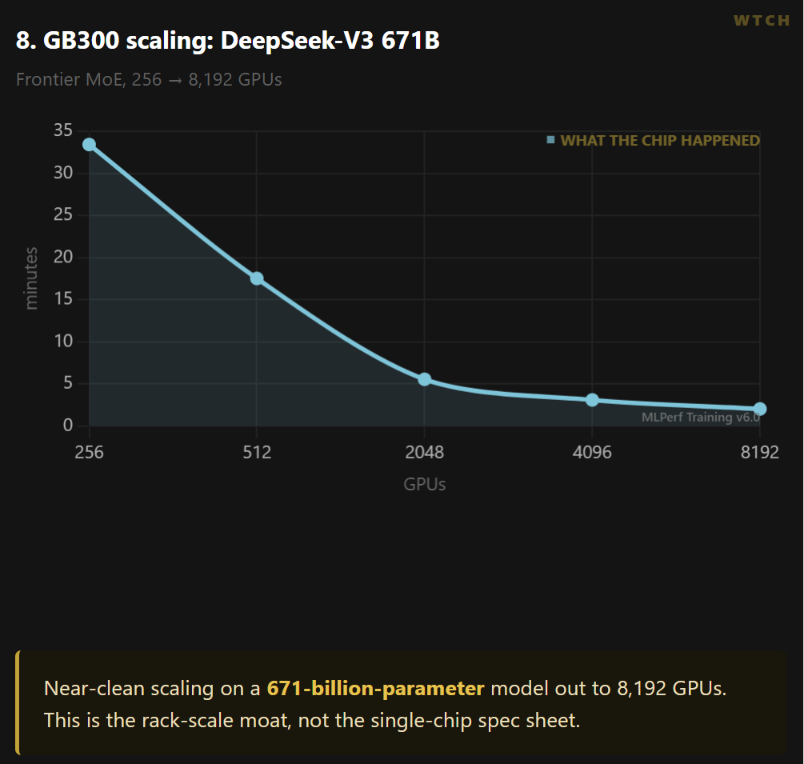
What it means for investors. A 4x-to-5x time-to-train improvement is the math that pulls forward a hardware refresh. For anyone modeling the Hopper-to-Blackwell upgrade cycle, this is the multiple that makes the capex pencil out.
3. AMD made real progress. The gap narrowed. It did not close.
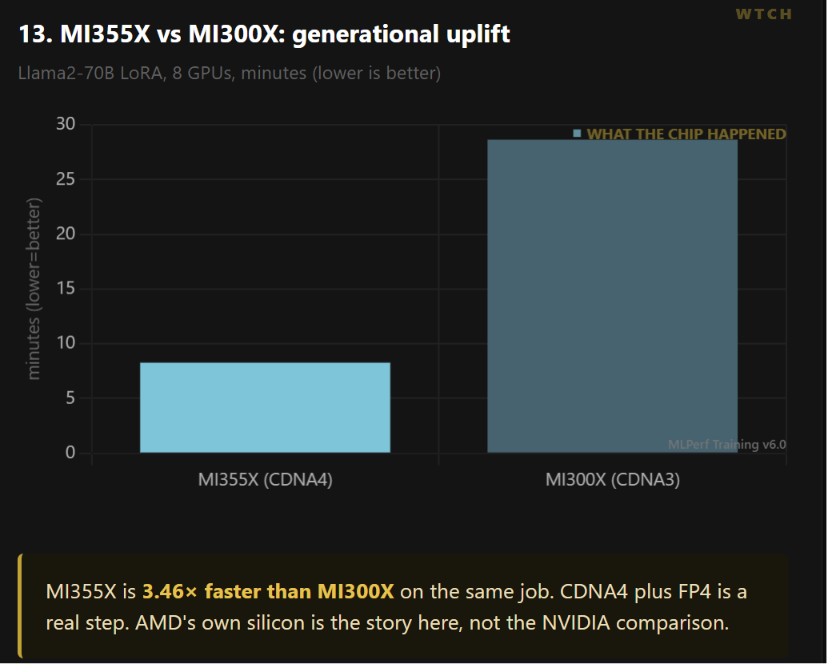
The bear case on AMD has always been “they never show up.” This round answers part of that.
MI355X (CDNA4) trains Llama2-70B LoRA in 8.27 minutes at 8 GPUs. The prior MI300X took 28.65 minutes on the same job. That is a 3.46x generational leap. CDNA4 plus four-bit math is a genuine step, and AMD’s own silicon is the story here more than the NVIDIA comparison.
On the head-to-head, MI355X lands mid-pack. It beats Hopper and sits ahead of GB200 on the LoRA job. Against the comparable 8-GPU Blackwell part, the B300, NVIDIA is still about 21 to 26 percent faster.
The homework for an AMD bull is now specific. Watch for the first MI355X result on DeepSeek-V3 or a 405B-class model at a thousand-plus GPUs. Until that prints, MLPerf positions AMD as a strong node-level option rather than a fleet-level NVIDIA replacement.
4. CoreWeave beat NVIDIA’s own number.
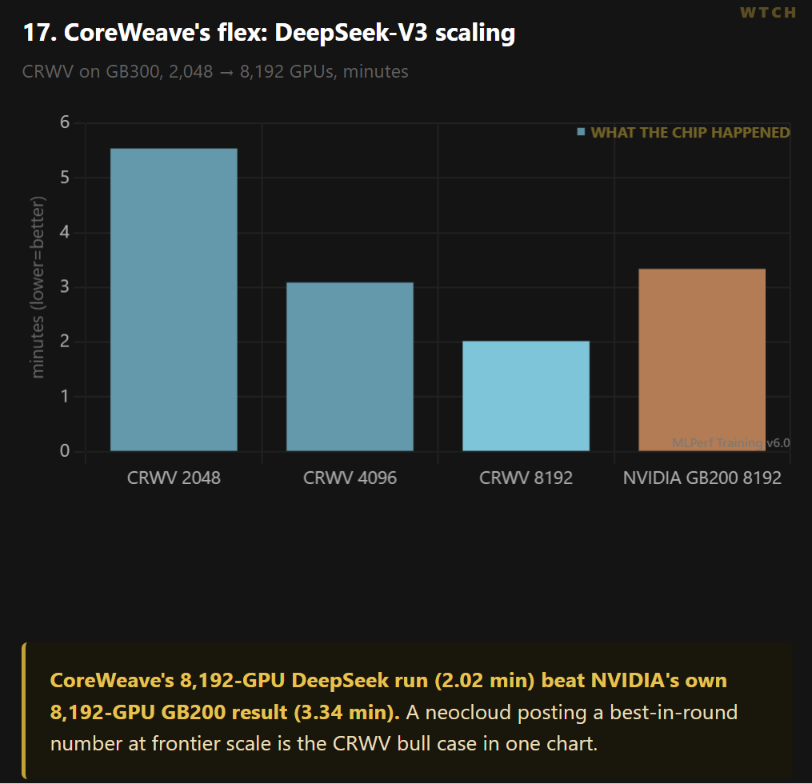
This is the result that should make GPU-cloud investors sit up.
CoreWeave (CRWV) ran DeepSeek-V3 671B at 8,192 GPUs on GB300 and finished in 2.02 minutes. NVIDIA’s own 8,192-GPU submission, running on the older GB200, came in at 3.34 minutes.
A pure-play neocloud posted the fastest DeepSeek result in the round, at frontier scale, ahead of NVIDIA’s first-party number. CoreWeave is also the only independent cloud on the list of jobs run at 2,048 GPUs or more.
Nebius (NBIS) showed up differently but credibly, with 12 results spread across Llama3.1-8B, GPT-OSS, and Flux.1 on the newest Blackwell silicon. The message there is “we have the latest chips and they work.”
What it means for investors. Submitting a clean, large-scale MLPerf result is a credibility signal to enterprise buyers deciding where to rent compute. CoreWeave just made that signal as loud as it gets.
5. The FP4 training era has quietly started.
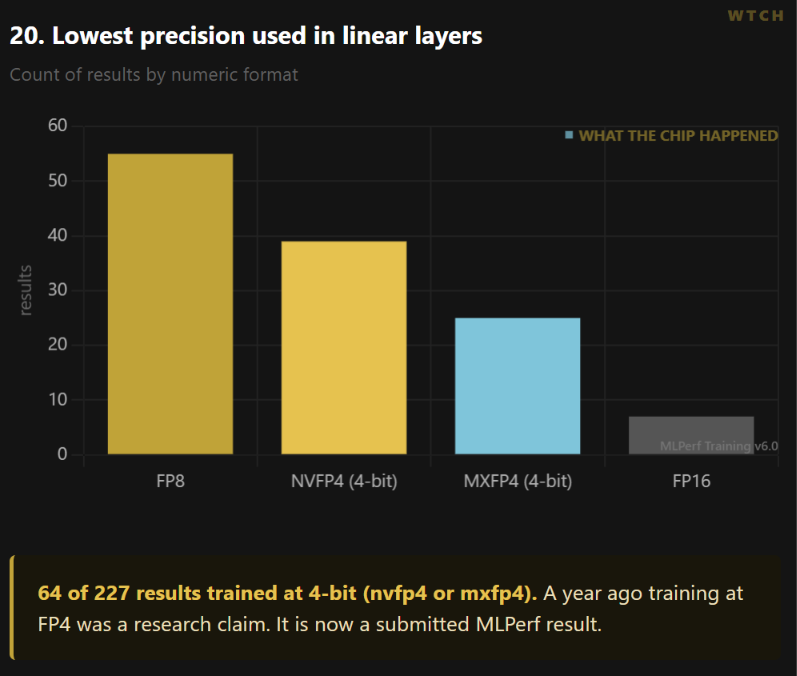
Here is the shift almost nobody is pricing.
64 of the 227 results trained at four-bit floating point. A year ago, training at FP4 was a research claim. It is now a submitted, validated MLPerf result.
The format is splitting. NVIDIA pushes its own NVFP4 across 39 results. AMD uses the open MXFP4 across 25. Two formats, two software stacks, and a real question about which one the model builders standardize on.
What it means for investors. Lower precision means more effective compute per dollar and per watt, which stretches every GPU already deployed. Whoever’s numerics the field adopts as the default earns a quiet software moat on top of the silicon. Track which format the large labs reach for first.
Get the full dashboard inside the community
I built the complete breakdown into an interactive dashboard: 20+ charts across seven angles, every one branded and ready to read, covering NVDA, AMD, CRWV, NBIS, the OEM channel, the scale leaderboard, and the precision war in full.
It is posted in the What The Chip Happened community, alongside various other dashboards covering Taiwan Supply Chain, Neocloud Players, and more.
Join the community and get the full 20+ chart MLPerf Training v6.0 dashboard →
Members get the dashboard, the live data tooling, and the tiered analysis on every name above. New members save 33 percent.!!
This is an educational summary of public benchmark data. It is not investment advice and not a recommendation to buy or sell any security. Benchmark results reflect specific submitted system configurations and may not represent real-world training performance. Author may hold positions in the companies mentioned. Do your own research.
Data: MLCommons MLPerf Training v6.0, Closed division, published results table.
I hope we’ll start seeing meaningful results and comparisons once the Instinct MI450 is released in a few months. In general, AMD is still a relatively small player with plenty of room to grow compared to the giant that is NVIDIA. Hyperscalers are likely to continue buying AMD products as well, both for performance reasons and to diversify their AI infrastructure away from a single dominant supplier. It’s much easier for a smaller company to grow rapidly than for the largest whale in the market to maintain the same pace of growth.